It was not easy: The development story of 'Danpung', the LLM for MapleStory Worlds
쉽지 않았습니다, 메이플 월드 자체 LLM ‘단풍’ 개발기
2026.06.16 16:23 UTC+9
AI Summary
NEXUS built a custom LLM named Danpung for MapleStory Worlds. The team overcame data shortages and vague user queries via GRPO. It was a tough lesson in building AI for niche scripting languages.

User-Generated Content (UGC) has recently become the talk of the town. With the allure of letting users—rather than just devs—craft their own experiences, giants like Roblox, Fortnite, and Genshin Impact are leaning hard into it. NEXUS Co., Ltd. jumped on this bandwagon back in 2022 with the launch of MapleStory Worlds, which has since carved out its own niche with hits like Mapleland, The Kingdom of the Winds: Classic, and Maple Planet.
However, the road for MapleStory Worlds wasn't exactly paved with gold. Since the platform relies on 'mlua', its own bespoke scripting language, off-the-shelf AI coding models were about as useful as a chocolate teapot. The team had to build their own Large Language Model (LLM) from scratch, affectionately dubbed 'Danpung'. We got the lowdown on the development saga at NDC 26 on the 16th, straight from Han Ji-sung of the NEXUS Co., Ltd. MapleStory Worlds Future Unit.
As mentioned, MapleStory Worlds uses 'mlua', a unique beast of a language. It doesn't just stick to standard structures; it’s packed with hundreds of proprietary APIs, making it a nightmare to integrate with general-purpose AIs like ChatGPT or Gemini. A dedicated LLM was effectively the only way forward.
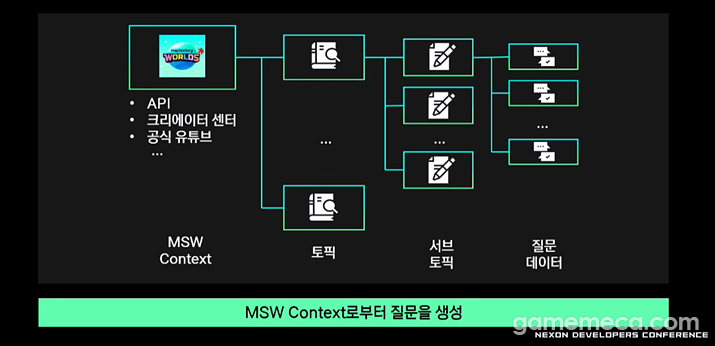
The biggest headache? A complete lack of training data. To bridge this gap, the team got creative, using their official creator centre and YouTube content to generate massive amounts of synthetic Q&A pairs. They broke topics down into sub-topics, turned them into questions, and used those for training. The resulting code then went through an automated grammar checker and a deduplication process to ensure the training material wasn't just fluff.
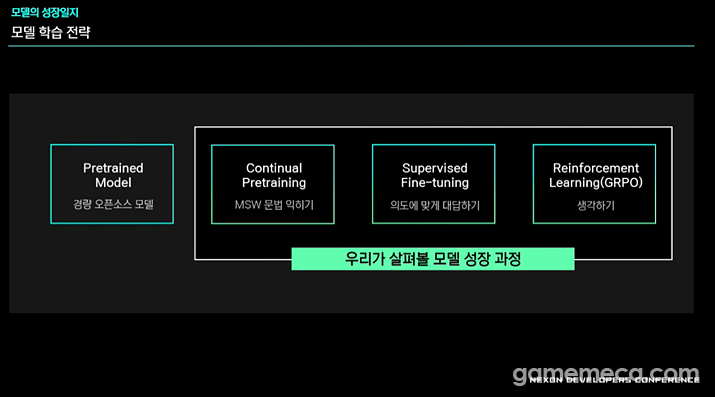
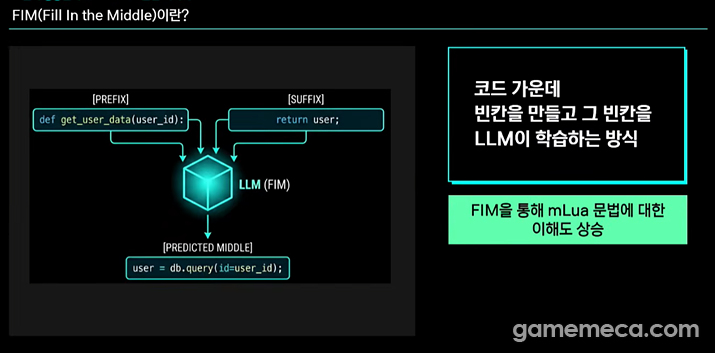
Han broke down the evolution of 'Danpung' into three distinct phases: Continual Pretraining (CPT), Supervised Fine-tuning (SFT), and Reinforcement Learning (GRPO). CPT was all about internalising the syntax of MapleStory Worlds. They fed it mathematical data to maintain logical reasoning while using a 'fill-in-the-blank' method for 'mlua' scripts to drill domain knowledge into the model.
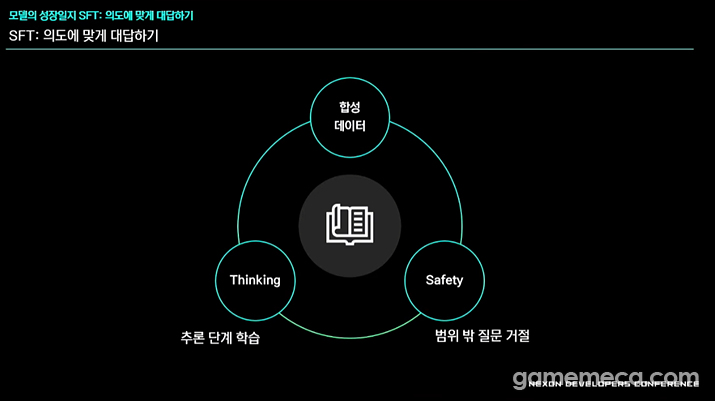
The second phase, SFT, aimed to align the model’s responses with user intent. By using synthetic, 'thinking', and safety-focused data, they significantly reduced the number of irrelevant answers and managed to get the AI to provide more natural key mappings and handy tips.
Yet, even then, the model suffered from hallucinations—confidently blurting out nonsense when asked about things outside the MapleStory Worlds ecosystem. To fix this, they introduced GRPO (Group Relative Policy Optimization). It’s a reinforcement learning technique that rewards accurate answers, forcing the model to 'think' before it speaks and, more importantly, to refuse answering if it doesn't know the score.

Even after such meticulous fine-tuning, the initial rollout had its hiccups. The safety protocols were initially so strict they were blocking legitimate programming queries. Plus, users weren't exactly writing essays; they preferred short, punchy, and often vague prompts. A request like 'I want to link this UI button to an event and log it' would just come in as 'make a UI'.
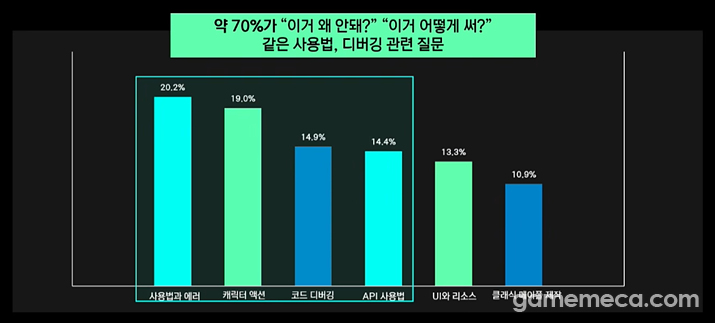
Recognising that most queries boiled down to 'how-to's', errors, character actions, or debugging, the team overhauled their training data and reward systems. Now, the model is much better at reading between the lines to deliver the correct solution despite those frustratingly brief inputs.

In his closing remarks, Han noted that the process was a massive learning curve. They realised the importance of an environment where you can actually verify if an LLM is doing its job. They also found that resource constraints limited them to basic grammar scripts, leaving gaps in helpfulness for users. Ultimately, it was a hard lesson in the necessity of efficient experimental strategies when resources are tight.
최근 UGC(User Generated Content)가 주목 받고 있다. 개발자가 아닌 유저가 직접 원하는 콘텐츠를 만들 수 있다는 매력 덕분에, 로블록스를 필두로 포트나이트, 원신 등 다양한 작품이 UGC 콘텐츠를 도입하는 추세다. 넥슨 역시 이러한 흐름에 맞춰 2022년 메이플스토리 월드를 선보였고, 이후 메이플랜드, 바람의 나라 클래식, 메이플플래닛 등 여러 콘텐츠가 화제를 모으며 시장에 당당히 자리잡았다.
하지만 메이플스토리 월드가 처음부터 순탄하게 개발됐던 것은 아니다. 특히 메이플스토리 월드는 자체 스크립트 언어인 ‘mlua’를 사용하는 만큼, 범용 AI 코드 생성 모델로는 개발이 어려웠다. 때문에 제작진은 자체 LLM 모델 ‘단풍’을 만들어 개발을 이어오고 있는데, 16일 진행된 NDC 26에서 ‘단풍’ 개발 비화에 대해 자세한 이야기를 들을 수 있었다. 강연에는 넥슨 메이플스토리 월드 퓨처유닛 한지성 개발자가 자리했다.
메이플스토리 월드는 앞서 언급했듯 ‘mlua’라는 독자적인 스크립트 언어를 활용한다. 이는 일반적인 구조에 더해, 수백 개의 자체 API를 사용하기 때문에 접근하기 매우 까다롭다. 그로 인해 챗GPT, 제미나이 등 범용적인 AI들은 적용이 다소 어려웠고, 전용 LLM 모델 구축이 불가피해졌다.
전용 모델을 만들기 위한 가장 큰 난관은 학습용 표본의 부재였다. 이에 개발진은 공식 크리에이터 센터와 유튜브 등 외부 거대 모델을 기반으로, 가상의 질문을 대량으로 만들어내 학습하는 방식을 고안했다. 해당 소스를 통해 토픽을 만들면 그것을 다시 여러 개의 서브 토픽으로 나누고, 이를 질문 데이터로 변환해 학습하는 구조다. 각 단계를 거쳐 완성된 코드는 다시 자동화된 문법 검사기와 중복 제거 절차를 통해 고품질의 학습 자료로 탈바꿈했다.
한지성 개발자는 이렇게 만들어진 ‘단풍’의 성장 과정을 CPT(Continual Pretraining), SFT(Supervised Fine-tuning), GRPO(Reinforcement Learning) 등 크게 세 단계로 요약했다. 먼저 CPT는 기본적인 메이플스토리 월드 문법을 익히기 위한 과정이다. 기존 모델의 추론 능력을 유지하기 위한 수학 데이터와 함께, ‘mlua’ 스크립트의 중간 빈칸을 채우는 기법을 적용하는 과정을 거쳐 도메인 지식과 문법을 주입했다.
두 번째로 SFT는 의도에 맞게 대답하도록 만드는 단계다. 이를 위해 합성 데이터, 사고(Thinking) 데이터, 안전성(Safety) 데이터 등 세 가지 요소를 기반으로 학습을 진행했다. 그 결과 질문에 상관없는 답변을 하는 경우가 눈에 띄게 줄었으며, 자연스러운 키 연결과 주요 팁도 함께 생성됐다.
다만 이 과정에서 메이플스토리 월드와 관련이 없는 질문에도 근거 없는 답변을 내놓는 할루시네이션 현상이 발생했다. 이를 방지하기 위해 진행된 것이 마지막 단계인 GRPO다. 이는 답변 정확도에 따라 보상을 차등 지급하는 강화학습 기법으로, 보상에 따른 이점을 계산해 더 나은 답변을 내놓도록 하는 기능이다. 이를 통해 ‘단풍’은 생각하는 과정을 통해 스스로 답변을 거절하는 기능이 생겼고, 더욱 정확한 답변이 가능해졌다.
이처럼 세밀한 학습 과정을 거쳤음에도, 실제 서비스가 시작된 직후에는 AI 안전 기준이 지나치게 높게 설정되어 정상적인 프로그래밍 질문마저 차단하는 부작용이 나타났다. 또한 유저들은 구체적인 상황 설명보다는 아주 단순하고 짧은 단어로 질문을 던지는 경향이 강했다. 예를 들어 ‘UI에 있는 버튼을 특정 이벤트와 연결하고 로그를 남기고 싶어’라는 질문이 ‘UI 만들어줘’로 축약되는 식이다.
이에 개발진은 유저 질의 상당수가 ‘사용법과 에러’, ‘캐릭터 액션’, ‘코드 디버깅’ 등 기초적인 사용법에 집중되어 있다는 점을 파악하고, 학습 자료와 보상 체계를 전면 수정했다. 그 결과 짧고 모호한 질문에도 작성자의 원래 의도를 유추하여 올바른 해결책을 제시할 수 있게 됐다.
마지막으로 한지성 개발자는 “이러한 과정 덕분에 배운 점도 많았다”고 전했다. 먼저 LLM 실제 실행 여부를 판단하기 어려워, 검증이 가능한 환경이 필요하다는 사실을 알게 됐다. 또한 워크스페이스 부족으로 인해 기본적인 문법 스크립트 위주 답변밖에 구현할 수 없어, 유저에게 도움이 되기에는 허점도 많았다. 그 외에도 제한된 자원을 사용할 수 밖에 없어, 효율적인 실험 전략의 필요성을 실감했다.
This news was translated by AI.

Lee Woo Min, Reporter
I will greet you with a good article.niro201@gamemeca.com
READ MORE
-
 Zeus: God of Hubris, Actress Park Ji-hyun Cast as NPC 'Pandora'
Zeus: God of Hubris, Actress Park Ji-hyun Cast as NPC 'Pandora'
-
 CEO Kim Ji-hoon: Subculture Users Desire the 'Pain' Extracted from Creators
CEO Kim Ji-hoon: Subculture Users Desire the 'Pain' Extracted from Creators
-
 AI in Game Narrative is Merely a Supplementary Tool with Clear Limitations
AI in Game Narrative is Merely a Supplementary Tool with Clear Limitations
-
 "A line that does not interfere with gameplay" EA Sports launches in-game advertising platform
"A line that does not interfere with gameplay" EA Sports launches in-game advertising platform
-
 Vivian Costume Added, Tomb Busters Shin-soo Theme Update
Vivian Costume Added, Tomb Busters Shin-soo Theme Update
-
 [Today's steam] 'Trend' Metcha Chameleon, 1 million more copies sold in a single day
[Today's steam] 'Trend' Metcha Chameleon, 1 million more copies sold in a single day
-
 PUBG AI Companion 'PUBG ELI' Beta Service Begins
PUBG AI Companion 'PUBG ELI' Beta Service Begins
-
 Idle RPG 'Wind Runner Idle' Pre-registration Opens, July Launch Announced
Idle RPG 'Wind Runner Idle' Pre-registration Opens, July Launch Announced

MOST POPULAR NEWS
- Girls' Frontline mobile competitive shooter development halted after 8 months
- POE 2, A 'Martyr' Appears Who Provided Server-Wide Buffs Through Max-Level 'Character Deletion'
- [Today's steam] New hide-and-seek game where you paint your own body to blend in draws attention
- The Elder Scrolls 6 reaches playable build stage
- Kairosoft Announces Restaurant Management Simulation Set in the One Piece Universe
- Development Resumes for Princess Maker: Children of the Prophecy, Update Scheduled for Late June
- Realistic Promotion Strategies Introduced by Small Indie Developers
- Agency that leaked MapleStory showcase information hit with 50 million KRW damages lawsuit
- [Weekly Game Comic] Dismissing the veteran meritorious retainer, Crazy Arcade BnB
- [Meca Ranking] What is your true form? TOP 5 abnormally light Pokemon
MEDIA PARTNERSHIPS


GAMEMECA SNS